Autovervollständigung meines Blogs
Seit letzter Woche basiert mein Blog auf Pelican, dem Python-basierten statischen Blog-Generator. Jetzt, da der Blog in einer Sprache erstellt wird, die ich mehr oder weniger beherrsche, kann ich darüber nachdenken, den Prozess des Schreibens und Erstellens selbst zu verbessern. Und natürlich gibt es viele Werkzeuge, die mir einfallen, um mein Leben sowie das Leben meiner Leser einfacher zu machen. Hier sind einige Beispiele für diese Helfer.
Werkzeuge, die ich gerne hätte
Bild-Tag-Vervollständigung (KI)
Immer wenn ich ein Bild ohne Alt-Text hinzufüge, ist das schlecht für blinde Menschen. Aber ich bin faul, warum also nicht eine KI das Bild beschreiben lassen und es als ALT-Text hinzufügen?
Link-Checker
Ich habe viele Links, die auf externe Seiten verweisen. Und manchmal verschwinden Webseiten, sodass meine Links ins Nirwana führen könnten. Es wäre schön, wenn
- meine Nutzer nicht auf defekte Links klicken müssten
- ich einen Hinweis bekäme, dass ich den einen oder anderen Link reparieren muss
- ich vielleicht die Situation verhindern könnte, indem ich eine Kopie der Seite, auf die ich verlinke, in meinem eigenen Blog behalte. Oder ist das böses Scraping und Content-Diebstahl?
Auszug-Generator (KI)
Ich schreibe oft Artikel, ohne die Zusammenfassung/den Auszug anzugeben, der in der Artikelliste angezeigt wird. Standardmäßig nimmt Pelican (und andere statische Generatoren) den ersten Absatz oder die ersten 30 Wörter und verwendet sie als Auszug.
Wäre es nicht viel schöner, ein LLM zu bitten, eine vernünftige dreizeilige Zusammenfassung zu erstellen?
Übersetzer (KI-ähnlich)
In meinem Blog schreibe ich manchmal englische, manchmal deutsche Artikel. Vielleicht gibt es hier und da sogar einen französischen Artikel. Wäre es nicht schön, jeden Artikel in jeder Sprache zu haben? Es fühlt sich an, als sollte das heutzutage Standard sein, angesichts der guten Qualität der heutigen Übersetzungstools.
Also schreibe ich meine Artikel in welcher Sprache auch immer, die gerade aus meinem kleinen Gehirn kommt, und das System sollte die fehlenden Sprachen generieren.
Artikelillustration (KI)
Ich versuche, für die meisten meiner Artikel Bilder zu haben, da es einfach ein angenehmeres Leseerlebnis ist und fürs Auge angenehm. Oft finde ich etwas im Internet, aber nicht immer - auch weil ich manchmal nicht einmal die Mühe mache, ein Bild zu suchen. Aber die KI könnte suchen oder sogar ein schönes Bild für meine nackten Artikel generieren.
Wir brauchen eine Build-Pipeline
Um diese Dinge zu erstellen, brauche ich eine Art Build-Pipeline:
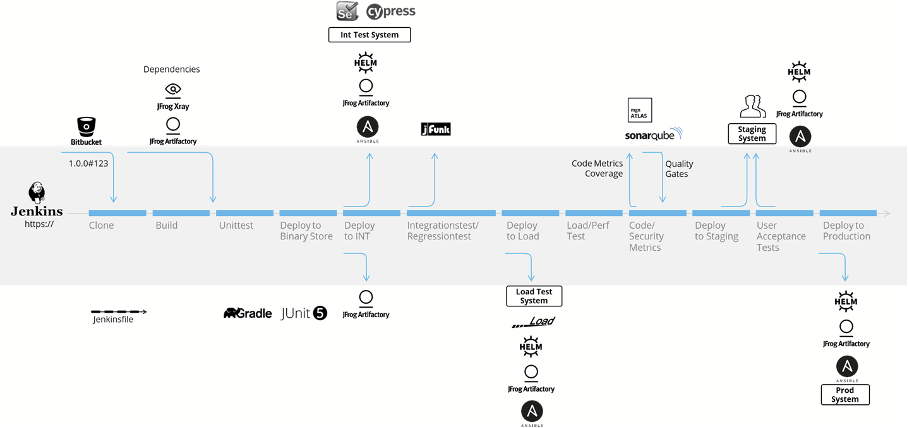 Eine moderne CI/CD-Build-Pipeline, entnommen von mgm technology partners
Eine moderne CI/CD-Build-Pipeline, entnommen von mgm technology partners
Einige Gedanken zur Struktur, Verarbeitung und Organisation von Daten.
Zwischenzeitliche Daten
Was Pelican macht, ist, die Quelle der Artikel zusammen mit der Konfiguration zu nehmen und die Webseiten zu generieren. Dies geschieht durch den Standardprozess und durch potenzielle Plugins. Plugins können von Drittanbietern oder selbst entwickelt sein. In meinem Fall habe ich beides.
Viele der Werkzeuge, die ich mir vorstelle, erzeugen zusätzliche Daten, und oft ist die Erstellung teuer und zeitaufwendig. Denken Sie daran, einen Auszug eines Artikels zu erstellen: Der gesamte Text muss an eine KI gesendet und verarbeitet werden. Dies dauert mehrere Sekunden und kostet echtes Geld. Daher ist es sicherlich nichts, das wir bei jedem Build ausführen möchten. Also müssen wir die Daten zwischen den verschiedenen Build-Läufen behalten.
Integrität der erstellten Inhalte
Eine Möglichkeit, dies zu lösen, wäre, den von der KI generierten Auszug einfach dem ursprünglichen Markdown hinzuzufügen (in diesem Fall würde er im Front Matter als summary-Feld erscheinen).
Aber das gefällt mir überhaupt nicht: Ich möchte nicht, dass die KI in den Text und Inhalt eingreift, den ich persönlich erstellt habe. Daher möchte ich die folgende Regel für mein System definieren:
Meine erstellten Markdown-Dateien sollten niemals von automatisierten Tools verändert werden.
Wo Daten aufbewahren
Das lässt mich mit der Frage, wo ich die Daten wie von der KI generierte Zusammenfassungen aufbewahren soll. Der natürliche Ort ist, sie neben den Markdown-Dateien zu halten, aber in einer eigenen Datei. Da ich separate Verzeichnisse für jeden meiner Artikel habe, erhalte ich diese Verzeichnis- und Dateistruktur:
content
articles
...
2025-04-18-digital-garden
2025-04-18-ditigal-garden.md
2025-04-18-digital-garden.picture-tags.json
2025-04-18-digital-garden.summary.json
digital-garden.jpg
Einige Gedanken und Argumente für diese Struktur:
- Jedes Werkzeug hat seine eigene Datei, um die Dinge getrennt zu halten.
- Ich verwende JSON-Dateien: Einfach zu verarbeiten und leicht zu lesen.
- Die Dateien befinden sich neben dem ursprünglichen Artikel, sodass alles, was zusammengehört, nah beieinander und gekapselt ist.
- Die JSON-Dateien werden auch versioniert und in Git gespeichert, sodass unabhängig davon, ob ich den Build-Prozess auf meiner lokalen Entwicklungsmaschine oder innerhalb von Github Actions oder einem anderen CI/CD-Prozessor ausführe, die zuvor generierten Daten wiederverwendet werden.
Verarbeitungsreihenfolge
Dieses Datenlayout erfordert einen mehrstufigen Build-Prozess:
- Zusätzliche Daten erstellen: Erstellen Sie die Zusammenfassungen, die Bildbeschreibungen, die Bilder, überprüfen Sie die Links (und speichern Sie das Ergebnis dieser Überprüfungen)… Dieser Prozess ist potenziell zeitaufwendig, erzeugt viele zusätzliche Daten und erfordert intelligente Caching- und Cache-Validierungsmechanismen. Z.B.“Wie überprüfe ich, ob ich die Zusammenfassung eines Artikels neu erstellen muss oder ob ich die im JSON-Datei neben dem Markdown-Artikel verwenden kann?”.
- Die Seite erstellen: Dies ist der grundlegende Pelican-Erstellungsprozess, wie wir ihn kennen, außer dass er auch die zusätzlichen Daten integrieren muss, die jetzt in den JSON-Dateien enthalten sind. Ich werde dies mit einem oder mehreren Pelican-Plugins tun, die ich entwickeln werde.